 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms for Batch Hierarchical Reinforcement Learning
Mar 29, 2016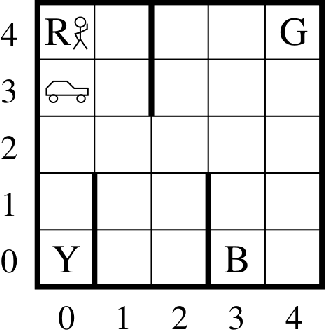
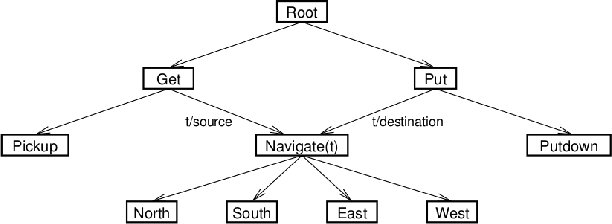
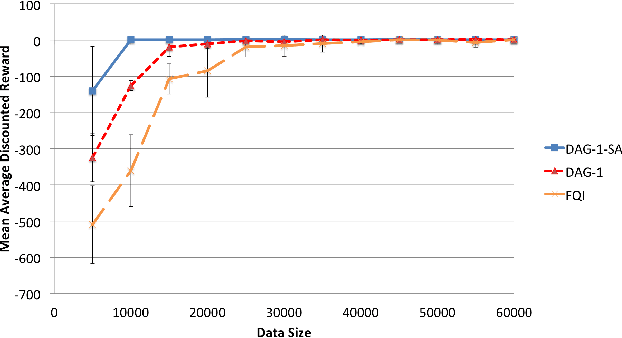
Hierarchical Reinforcement Learning (HRL) exploits temporal abstraction to solve large Markov Decision Processes (MDP) and provide transferable subtask policies. In this paper, we introduce an off-policy HRL algorithm: Hierarchical Q-value Iteration (HQI). We show that it is possible to effectively learn recursive optimal policies for any valid hierarchical decomposition of the original MDP, given a fixed dataset collected from a flat stochastic behavioral policy. We first formally prove the convergence of the algorithm for tabular MDP. Then our experiments on the Taxi domain show that HQI converges faster than a flat Q-value Iteration and enjoys easy state abstraction. Also, we demonstrate that our algorithm is able to learn optimal policies for different hierarchical structures from the same fixed dataset, which enables model comparison without recollecting data.
EESEN: End-to-End Speech Recognition using Deep RNN Models and WFST-based Decoding
Oct 18, 2015

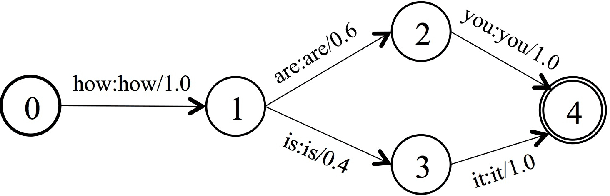

The performance of automatic speech recognition (ASR) has improved tremendously due to the application of deep neural networks (DNNs). Despite this progress, building a new ASR system remains a challenging task, requiring various resources, multiple training stages and significant expertise. This paper presents our Eesen framework which drastically simplifies the existing pipeline to build state-of-the-art ASR systems. Acoustic modeling in Eesen involves learning a single recurrent neural network (RNN) predicting context-independent targets (phonemes or characters). To remove the need for pre-generated frame labels, we adopt the connectionist temporal classification (CTC) objective function to infer the alignments between speech and label sequences. A distinctive feature of Eesen is a generalized decoding approach based on weighted finite-state transducers (WFSTs), which enables the efficient incorporation of lexicons and language models into CTC decoding. Experiments show that compared with the standard hybrid DNN systems, Eesen achieves comparable word error rates (WERs), while at the same time speeding up decoding significantly.